How Image Stacking WorksImage stacking is a popular method of image processing amongst astrophotographers, although the exact same technique can be applied to any situation where identical images can be captured over a period of time, in other words in situations where the scene isn't changing due to motion or varying light and shadow. Astrophotography happens to be perfectly suited in this manner, in that astronomical objects are effectively static for reasonable durations of time. In the case of deep sky objects, the objects are virtually permanant. In the case of planetary images, they change slowly enough that a series of images spanning at least a few minutes can be acquired without observable motion. The first time I witnessed the effects of image stacking, I was completely blown away by the result. It seems almost magical that so much real information can be gleaned from such horrible original images. But of course the real explanation is quite simple to understand. Image stacking does two very different things at once. It increases the signal-to-noise ratio and increases the dynamic range. I will discuss each of these separately. 
One point of confusion that should be resolved early on is whether there is a difference between averaging and summing. Since this remains an issue of contention I can only claim that my explanation makes sense. If one doesn't follow my explanation, then one might disagree with me. The short answer is that they are identical. It doesn't make any difference whether you stack into a sum or an average. This claim assumes that an average is represented using floating point values however. If you average into integer values then you have thrown away a lot of detailed information. More precisely, I maintain that there is a continous range of representations of a stack varying between a sum and an average, which simply consist of dividing the sum by any number between one and the number of images stacked. In this manner, it is obvious that summing and averaging are identical and contain the same fundamental information. Now, in order to actually view a stack, the values must somehow be transformed into integer components of an image's brightness at each pixel. This isn't easier or harder to accomplish with a sum or a stack, as neither properly fits the necessary requirements of standard image representations. The sum contains values that are way off the top of the maximum possible value that can be represented, and the average contains floating point values which cannot be immediately interpretted as image pixels without conversion to integers first. The solution in both cases is the exact same mathematical operation. Simply find the necessary divisor to represent the brightest pixel in the stack without saturating, and then divide all pixels in the image by that divisor and convert the divided values to integers. Again, since the transformation is identical in both cases, clearly both forms contain the same information. The only reason I harp on this so much is that it must be properly understood before one can really comprehend what stacking is doing, which is actually extremely simple once you get down to it.
The classic application of image stacking is to increase the signal-to-noise ratio (snr). This sounds technical and confusing at first, but it is really simple to understand. Let's look at it in parts and then see how the whole thing works. The first thing you must realize is that this is a pixel-by-pixel operation. Each pixel is operated on completely independent of all other other pixels. For this reason, the simplest way to understand what is going on is to imagine that your image is only a single pixel wide and tall. I realize this is strange, but bear with me. So your image is a single pixel. What is that pixel in each of your raw frames? It is the "signal", real photons that entered the telescope and accumulated in the CCD sensor of the camera, plus the thermal noise of the CCD and the bias along with any flatfield effects...plus some random noise thrown in for good measure. It is this last element of noise that we are concerned with. The other factors can be best handled through operations such as darkframe subtraction and flatfield division. However, it is obvious that after performing such operations to a raw, we still don't have a beautiful image, at least compared to what can be produced by stacking. Why is this? The problem is that last element of random noise. Imagine the following experiment: pick random numbers (positive and negative) from a Gaussian distribution centered at zero. Because the distribution is Gaussian, the most likely value is exactly zero, but on each trial (one number picked), you will virtually never get an actual zero. However, what happens if you take a whole lot of random numbers and average them. Clearly, the average of your numbers approaches zero more and more closely, the more numbers you pick, right? This occurs for two reasons. First, since the Gaussian is symmetrical and centered at zero, you have a one in two changes of picking a positive or negative number on each trial. On top of that, you have a greater chance of picking numbers with a low absolute value due to the shape of the Gaussian. When combined, these two reasons demonstrate clearly that the average of a series of randomly chosen numbers (from this distribution) will converge assymptotically toward zero (without every truly reaching zero of course). Now imagine that this Gaussian distribution of random numbers represents noise in your pixel sample. If you are also gathering real light at the same time as the noise, then the center of the Gaussian won't be zero. It will be the true value of the object you are imaging. In other words, the value you record with the CCD in a single image equals the true desired value plus some random Gaussian-chosen value, which might make the recorded value less than the true value or might make it greater than this value. ...but we just established that repeated samples of the noise approach zero. So what stacking really does is repeatedly sample the value in question. The real true value never actually changes, in that the number of photons arriving from the object is relatively constant from one image to the next. Meanwhile, the noise component converges on zero, which allows the stacked value to approach the true value over a series of stacked samples. That's it as far as the snr issue is concerned. It's pretty simple isn't it.
Another task that stacking accomplishes, which is not toted too much in the literature but which is of great importance to deep sky astrophotographers, is increase the dynamic range of the image. Of course this can only be understood if you already understand what dynamic range is in the first place. Simply put, dynamic range represents the difference between the brightest possible recordable value and the dimmest possible recorded value. Values greater than the brightest possible value saturate (and are therefore ceilinged as the brightest possible recordable value instead of their actual value), while values dimmer than the dimmest possible value simply drop off the bottom and are recorded as 0. First understand how this works in a single raw frame captured with a CCD sensor. CCDs have an inherant sensitivity. Light that is too dim for their sensitivity simply isn't recorded at all. This is the lower bound, the dimmest possible value that can be recorded. The simplest solution to this problem is to exposure for a longer period of time, to get the light value above the dimmest recordable value so it will in fact be recorded. However, as the exposure time is increased, the value of the brightest parts of an image increases along with the value of the dimmest parts of the image. At the point where parts of the image saturate, and are recorded as the brightest possible value instead of their true (brighter) value, the recording is overloaded and crucial information is lost. Now you can understand what dynamic range means in a CCD sensor and a single image. Certain objects will have a range of brightness that exceeds the range of brightness that can be recorded by the CCD. The range of brightness of the object is its actual dynamic range, while the range of recordable brightness in the CCD is the CCD's recordable dynamic range. The following illustration shows the concepts described above. Notice that there is no one perfect exposure time for an object. It depends on whether you are willing to lose the dim parts to prevent saturation of the bright parts or whether you are willing to saturate the bright parts to get the dim parts. Stacking only aids this problem to a limited degree, as described below. Once the limits of stacking have been reached in this regard more complicated approaches must be used, such as mosaicing, in which a short exposure stack is blended with a long exposure stack, such that each stack only contributes the areas of the image in which it has useful information. 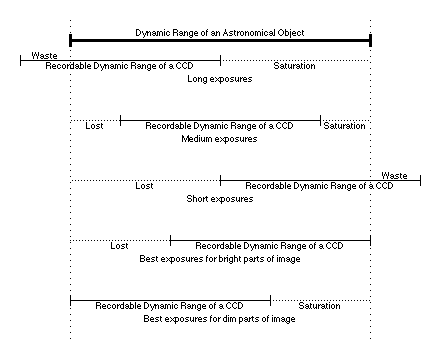
CCDs are analog devices (or digital at the scale of photons in the CCD wells and electrons in the wires sending electrical signals from the CCD to the computer). However, analog devices send their signals through analog/digital converters (A/D converters) before sending the digial information to the computer. This is convenient for computers, but it introduces an arbitrary point of dynamic range constraint into the imaging device that theoretically doesn't need to be there. An analog device would theoretically have great dynamic range, but suffers from serious noise problems (this is why digital long distance and cellular phones sound better than analog ones). The question is, how does the A/D converter affect the dynamic range, or in other words, since all we care about is the end product, what exactly is the dyamic range of the image coming out of the A/D converter. The answer is that different cameras produce different numbers of digital bits. Webcams usually produce 8 bits while professional cameras usually produce twelve to sixteen bits. This means that professional cameras have sixteen to 256 times more digitized values with which to represent brightnesses compared to a webcam, which means that as you crank up the exposure time to get the dim parts of an object within the recordable range, you have more room left at the top of your range to accomodate the brightest parts of the object before they saturate. So what does stacking do? The short answer is that it increases the number of possible digitized values linearly with the number of images stacked. So you take a bunch of images that are carefully exposed so as not to saturate the brightest parts. This means you honestly risk losing the dimmest parts. However, when you perform the stack, the dimmest parts accumulate into higher values that escape the floor of the dynamic range, while simultaneously increasing the dynamic range as the brightest parts get brighter and brighter as more images are added to the stack. It is as if the max possible brightest value keeps increasing just enough to stay ahead of the increasing brightness of the stacked values of the brightest pixels, if that makes sense. In this way, the stacked image contains both dim and bright parts of an image without losing the dim parts off the bottom or the bright parts off the top. Now, it should be immediatel obvious that there is something slightly wrong here. If the raw frames were exposed with a short enough time period to not gather the dim parts at all, because the dim parts were floored to zero, then how were they accumulated in the stack? In truth, if the value in a particular raw falls to zero, it will contribute nothing to the stack. However, imagine that the true value of a dim pixel is somewhere between zero and one. The digitization of the A/D converter will turn that value into a zero, right? Not necessarily. Remember, there is noise to contend with. The noise is helpful here, in that the recorded value of such a pixel will sometimes be zero and sometimes be one, and occasionally even two or three. This is true of a truly black pixel with no real light of course, but in the case of a dim pixel, the average of the Gaussian will be between zero and one, not actually zero. When you stack a series of samples of this pixel, some signal will actually accumulate, and the value will bump up above the floor value of the stacked image, which is simply one of course. Interestingly, it is easy to tell which parts of an image have a true value that is lower than one in a each raw frame. If the summed value of a pixel is less than the number of images in the stack, or if the average value of the pixel is a floating point value below one, then clearly the true value must be below one in the raw frames because some of the raw frames must have contributed a zero to the stack in order for the stacked value to be less than the number of images stacked after a sum is produced. (This does not take into account that there is of course some noise at play here as well, which means a pixel with a true value of 1.5 might get a zero from some raw frames, but the stacked value should, in theory, be greater than one in the averaged stack of course). There is another factor at play here too. The Gaussian distribution is about the same shape (variance or standard deviation) regardless of the brightess of the actual pixel, which means the noise component of a pixel is much more severe for dim pixels than for bright pixels. Therefore, stacking allows you to bright the value of dim pixels up into a range where they wont be drowned out by the noise...while at the same time decreasing the noise anyway, as per the description in the first half of this article. This is another crucial aspect of how stacking allows dim parts of an image to become apparent. It is for this same reason that, in each raw frame, the bright parts, although noisy, are quite discernable in their basic structure, while the dim parts can appear virtually incomprehensible. So that's what stacking does. Pretty neat, huh? |